The String functions evaluate string values and fields.
This function accepts a string value X as input. It evaluates the character length of the string and returns the count of the number of characters in the string.
Syntax:
| process eval("identifier=len(X)")
Example:
| process eval("message_length=len(message)")
| fields message, message_length
The above example counts the length of the character in the message field and returns the result in the message_length identifier.
The fields command displays the value of the message and message_length in a tabular form.

Len function¶
This function accepts up to three arguments, a string value X, a start index and an end index. It evaluates the substring of the string X and returns the substring that starts at the index specified by start_index and ends at the index specified by end_index. Here the end_index is exclusive.
Syntax:
| process eval("identifier=substr(X, start_index, end_index)")
Example:
| process eval("substring=substr(col_type, 0, 4)")
The above example returns the substring of the value of the col_type event, starting at index 0 and ending at index 4, in the substring identifier.

Substr function¶
This function accepts only one string argument X as input. It converts the string to lowercase and returns the converted string value.
Syntax:
| process eval("identifier=lower(X)")
Example:
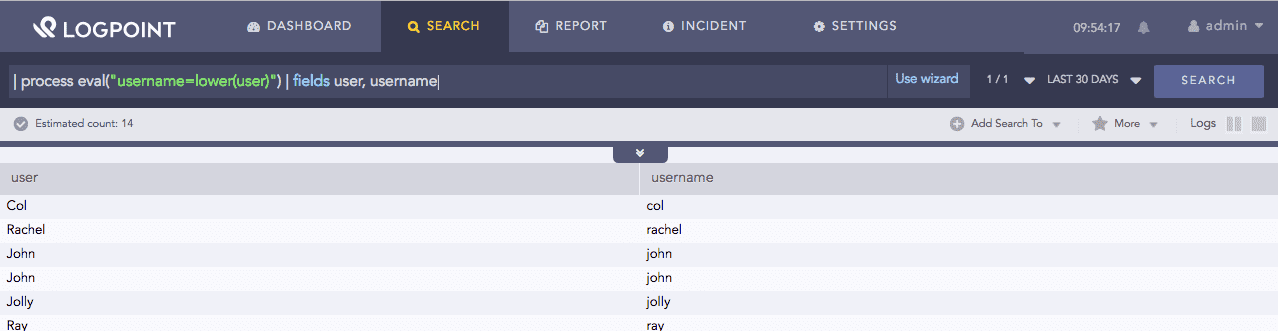
| process eval("username=lower(user)") | fields user, username
The above example converts the value of the user field to lowercase and returns it in the username identifier.
The fields command displays the value of user and username in a tabular form.
Lower function¶
This function accepts only one string argument X as input and converts the string to uppercase and returns the converted string value.
Syntax:
| process eval("identifier=upper(string_value)")
Example:
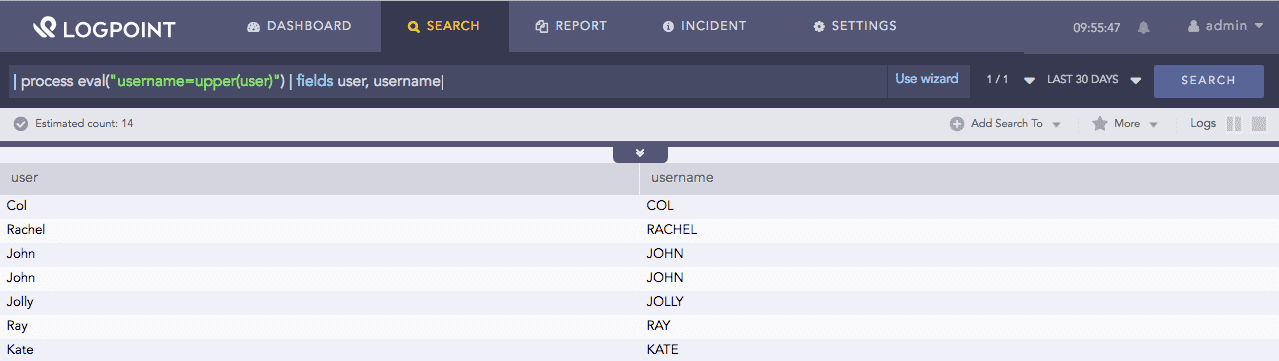
| process eval("username=upper(user)") | fields user, username
The above example converts the value of the user field to uppercase and returns it in the username identifier.
The fields command displays the value of user and username in a tabular form.
Upper function¶
This function accepts only one string argument X. It trims the spaces to the left and right in the string and returns a trimmed value. Trailing spaces are the white spaces located at the end of a line, without any other characters following it, for example blank spaces and tabs.
Syntax:
| process eval("identifier=trim(X)")
The above example removes the spaces to the left and right from the Bob and returns the trimmed value in the username identifier.
Example:
| process eval("username=trim(' Bob ')")

Trim function¶
This function accepts up to two string arguments X and Y as inputs. It trims the string Y from the left side of the field X and returns a trimmed value. If Y is not defined, it trims the spaces from the left side.
Syntax:
| process eval("identifier=ltrim(X, Y)")
Example:
| process eval("result=ltrim(device_name, 'local')")
The above example removes the string local from the left side in the value of the device_name field and returns the trimmed value in the result identifier.

Ltrim function¶
This function takes up to two string arguments X and Y as inputs. It trims the strings Y from the right side of the field X and returns a trimmed value. If Y is not defined, it trims the trailing spaces from the right side.
Syntax:
| process eval("identifier=rtrim(X, Y)")
Example:
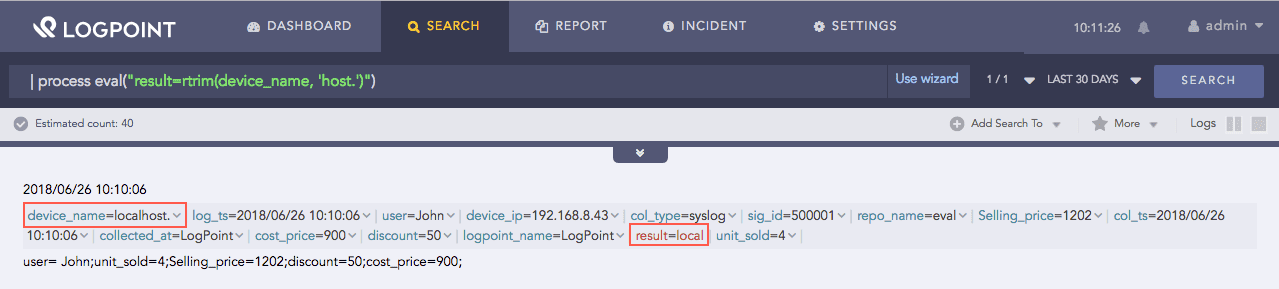
| process eval("result=rtrim(device_name, 'host')")
The above example removes the string host from the right side in the value of the device_name field and returns the trimmed value in the result identifier.
Rtrim function¶
This function accepts three arguments as inputs: a string X, a regex string Y, and a string Z. It substitutes the string Z in the string X for every occurrence of the regex string Y and returns a string value.
Syntax:
| process eval("identifier=replace(X, Y, Z)")
Example:
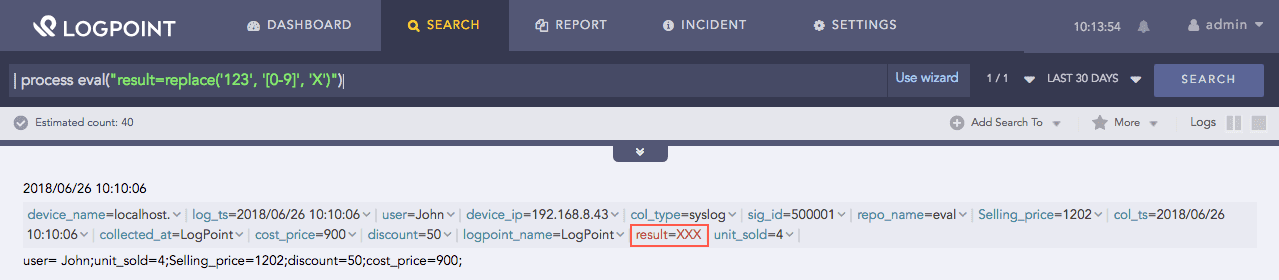
| process eval("result=replace('123', '[0-9]', 'X')")
The above example substitutes ‘X’ in the string 123 for the every occurence of the regex string [0-9] and returns the replaced value in the result identifier.
Replace function¶
This function accepts two arguments, X and Y, where X is the structured data type in XML or JSON format, and Y is the XML or JSON formatted location path. It returns a value extracted from the structured data type in X, based on the location path in Y.
Syntax:
| process eval("identifier=spath(X, Y)")
Example 1:
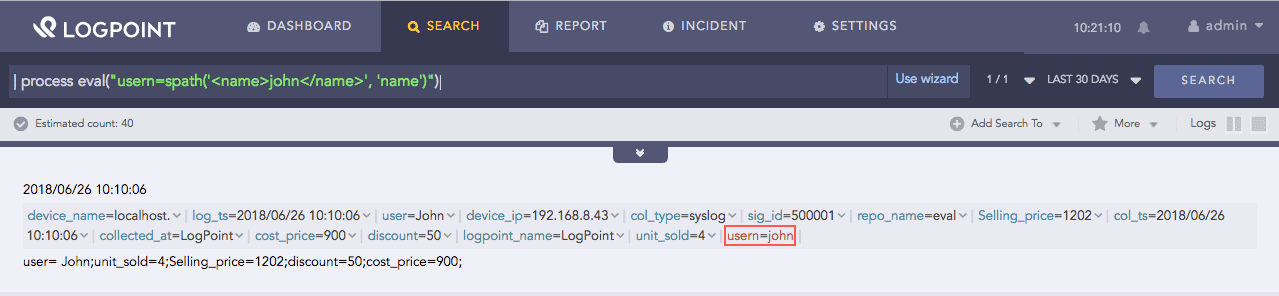
| process eval("usern=spath('<name>john</name>', 'name')")
The above example extracts the value from the location name and returns it in the usern identifer.
Spath function¶
Example 2:
| process eval("usern=spath('{name:\john\}', 'name')")
The above example extracts the value from the location name: and returns it in the usern identifer. The result is usern=john.
Note
For JSON format data,
Keys must be without quotes. LogPoint currently does not support nested quotes.
If the value of any key is a string, replace quote with backslash as shown in Example 2 above.
For example, the JSON data is in a key-value pair. Where, keys and values must be within double quotes {“name”:”John”}. However, while using the spath function, the JSON data is written as {name:\john\}.
This function accepts an escaped URL character X and returns the decoded or unescaped URL string.
Syntax:
| process eval("identifier=urldecode(X)")
Example:
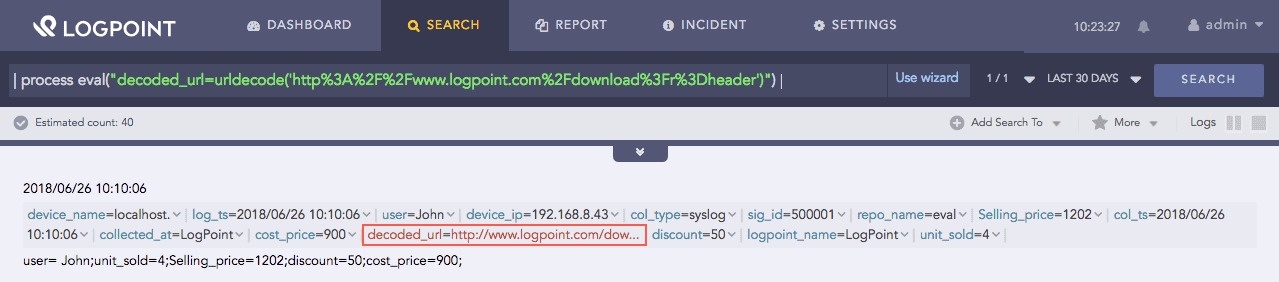
| process eval("decoded_url=urldecode('http%3A%2F%2Fwww.logpoint.com%2Fdownload%3Fr%3Dheader')")
The above example decodes an escaped url and returns the decoded url, i.e., http://www.logpoint.com/download?r=header in the decoded_url identifier.
Urldecode function¶